作者:--Fac_k- | 来源:互联网 | 2023-09-12 14:03
篇首语:本文由编程笔记#小编为大家整理,主要介绍了sparkstreaming之实时数据流计算实例相关的知识,希望对你有一定的参考价值。最近在用sparkstreamin
篇首语:本文由编程笔记#小编为大家整理,主要介绍了sparkstreaming之实时数据流计算实例相关的知识,希望对你有一定的参考价值。
最近在用sparkstreaming的技术来实现公司实时号码热度排序,学习了一下sparkstreaming的相关技术,今天主要要讲一个简单sparkstreaming实时数据流技术的一个示例,帮助大家更好的理解和学习sparkstreaming编程原理。
在开始实例之前我们简单的了解一下sparkstreaming的原理:具体参见:http://m635674608.iteye.com/blog/2248368
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
Spark Streaming处理的数据流图:

Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
Spark Streaming实时计算框架
Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势在于:
- 能运行在100+的结点上,并达到秒级延迟。
- 使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
- 能集成Spark的批处理和交互查询。
- 为实现复杂的算法提供和批处理类似的简单接口。
基于云梯Spark on Yarn的Spark Streaming总体架构如图1所示。其中Spark on Yarn的启动流程我的另外一篇文章(《程序员》2013年11月期刊《深入剖析阿里巴巴云梯Yarn集群》)有详细描述,这里不再赘述。Spark on Yarn启动后,由Spark AppMaster把Receiver作为一个Task提交给某一个Spark Executor;Receive启动后输入数据,生成数据块,然后通知Spark AppMaster;Spark AppMaster会根据数据块生成相应的Job,并把Job的Task提交给空闲Spark Executor 执行。图中蓝色的粗箭头显示被处理的数据流,输入数据流可以是磁盘、网络和HDFS等,输出可以是HDFS,数据库等。
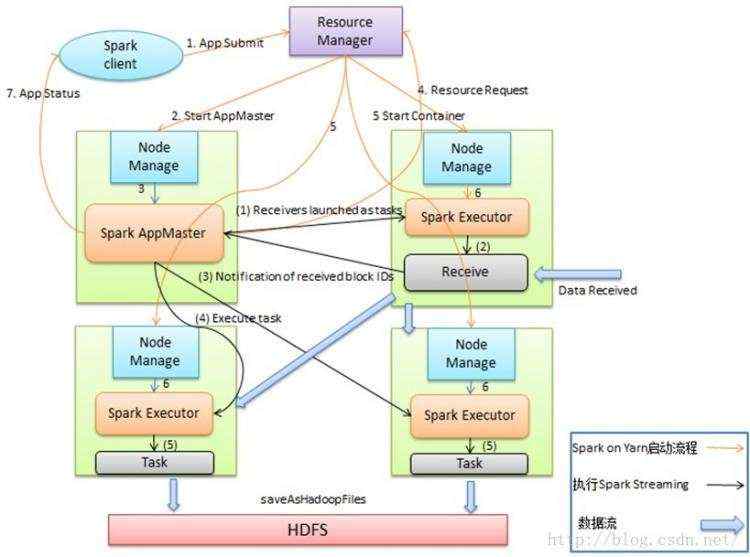
图1 云梯Spark Streaming总体架构
Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据,其基本原理如图2所示。

图2 Spark Streaming基本原理图
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
下面介绍Spark Streaming内部实现原理。
使用Spark Streaming编写的程序与编写Spark程序非常相似,在Spark程序中,主要通过操作RDD(Resilient Distributed Datasets弹性分布式数据集)提供的接口,如map、reduce、filter等,实现数据的批处理。而在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。图3和图4展示了由Spark Streaming程序到Spark jobs的转换图。
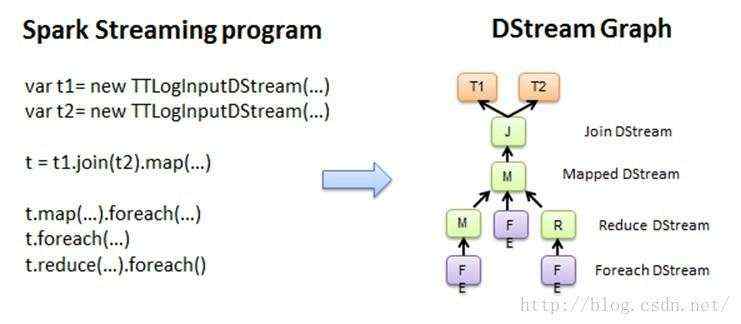
图3 Spark Streaming程序转换为DStream Graph

图4 DStream Graph转换为Spark jobs
在图3中,Spark Streaming把程序中对DStream的操作转换为DStream Graph,图4中,对于每个时间片,DStream Graph都会产生一个RDD Graph;针对每个输出操作(如print、foreach等),Spark Streaming都会创建一个Spark action;对于每个Spark action,Spark Streaming都会产生一个相应的Spark job,并交给JobManager。JobManager中维护着一个Jobs队列, Spark job存储在这个队列中,JobManager把Spark job提交给Spark Scheduler,Spark Scheduler负责调度Task到相应的Spark Executor上执行。
Spark Streaming的另一大优势在于其容错性,RDD会记住创建自己的操作,每一批输入数据都会在内存中备份,如果由于某个结点故障导致该结点上的数据丢失,这时可以通过备份的数据在其它结点上重算得到最终的结果。
正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任。另外通过RDD的数据重用机制可以得到更高效的容错处理。
了解了sparkstreaming的工作原理后,我们来开始我们的实时处理实例编程吧
首先我们要做一个日志生产器,方便本地模拟线上环境:
直接上代码吧(原理是根据一个原始日志log,然后随机的从中挑选行添加到新生产的日志中,并且生产的数据量呈不断的增长态势)
import java.io._
import java.text.SimpleDateFormat
import org.apache.spark.SparkConf, SparkContext
import java.util.Date
import java.io.PrintWriter
import scala.io.Source
import scala.util.matching.Regex
object FileGenerater
def main(args: Array[String])
var i=0
while (i<100 )
val filename &#61; args(0)
val lines &#61; Source.fromFile(filename).getLines.toList
val filerow &#61; lines.length
val writer &#61; new PrintWriter(new File("/Users/mac/Documents/workspace/output/sparkstreamingtest"&#43;i&#43;".txt" ))
i&#61;i&#43;1
var j&#61;0
while(j
writer.write(lines(index(filerow)))
println(lines(index(filerow)))
j&#61;j&#43;1
writer.close()
Thread sleep 5000
log(getNowTime(),"/Users/mac/Documents/workspace/output/sparkstreamingtest"&#43;i&#43;".txt generated")
def log(date: String, message: String) &#61;
println(date &#43; "----" &#43; message)
/**
* 从每行日志解析出imei和logid
*
**/
def index(length: Int) &#61;
import java.util.Random
val rdm &#61; new Random
rdm.nextInt(length)
def getNowTime():String&#61;
val now:Date &#61; new Date()
val datetimeFormat:SimpleDateFormat &#61; new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val ntime &#61; datetimeFormat.format( now )
ntime
/**
* 根据时间字符串获取时间,单位(秒)
*
**/
def getTimeByString(timeString: String): Long &#61;
val sf: SimpleDateFormat &#61; new SimpleDateFormat("yyyyMMddHHmmss")
sf.parse(timeString).getTime / 1000
下面给出我们程序的configuration&#xff1a;

zhangfusheng.txt内容如下&#xff1a;
安徽 宿州市 汽车宿州分公司 王红岩 18955079 20538
浙江 嘉兴市 汽车海宁分公司 金韩伟 15305793 15703
安徽 滁州市 汽车滁州分公司 严敏 15385906 14403
湖北 武汉市 汽车湖北汽车服务分公司 张晴 18902923 10870
安徽 淮北市 汽车淮北分公司 李亚 15305501 10484
安徽 滁州市 汽车滁州分公司 王旭东 153055412 10174
安徽 淮南市 汽车淮南分公司 尹芳 181096430 10085
湖北 省直辖行政单位 汽车仙桃分公司 汤黎 189170533 9638
湖北 null 汽车潜江分公司 朱疆振 18996689 9479
安徽 宣城 汽车宣城分公司 李倩 18098229 9381
江苏 徐州 丰县分公司 李萍 18914805005 9340 归属地
安徽 滁州市 汽车滁州分公司 阚家萍 15304795 9180
广东 中山 汽车服务中心 农小萍 18070101 9095 归属地
湖北 孝感 汽车孝感分公司 黄燕平 189957628 8595 归属地
安徽 芜湖 null 邹恒清 18055349069 8537 归属地
江西 null 汽车江西分公司产品事业部(汽车服务分公司、互联网安全管理中心) 张凯 17118 8089
安徽 淮南市 汽车淮南分公司 李磊 18957707 8039
湖北 省直辖行政单位 汽车仙桃分公司 朱艳 189770380 8025
浙江 温州 汽车温州分公司(本部) 吴玉春 153050010 7729 归属地
安徽 淮北市 汽车淮北分公司 魏薇 15305232 7533
湖北 省直辖行政单位 汽车仙桃分公司 王雪纯 18972060 7405
湖北 宜昌市 汽车宜昌分公司 刘丽娟 189086005 7269
湖北 武汉市 汽车湖北汽车服务分公司 陶劲松 189182796 7209
安徽 淮北 汽车合肥分公司 刘洁 181561187 7108 归属地
湖北 null 宜昌电信公司 鲜艳 18908606 7000
安徽 淮北市 汽车淮北分公司 钱玉 105612841 6837
湖北 武汉市 汽车湖北汽车服务分公司 谢真华 187181833 6757
安徽 null 马鞍山公司 张颖 153096590 6710
安徽 芜湖市 汽车芜湖分公司 许丽丽 155535300 6694
安徽 合肥市 汽车合肥分公司 杨华丽 15305168 6666
安徽 铜陵市 汽车铜陵分公司 黄琳 153629216 6665
安徽 马鞍山 汽车马鞍山分公司 林花 13395726 6487
贵州 null 汽车贵州分公司10000号运营中心 陈宣宏 189101372 6421
安徽 合肥市 汽车合肥分公司 黄乐 153005266 6271
安徽 淮南市 汽车淮南分公司 赵乃艳 153058367 6263
湖北 武汉市 汽车湖北汽车服务分公司 蔡蕾 189076931 6218
湖北 null 汽车潜江分公司 陈晓辉 18996898 6176
安徽 马鞍山市 汽车马鞍山分公司 陈凤 15305365 6116
安徽 合肥市 汽车合肥分公司 李大燕 18096819 6036 我先来观察一下运行结果&#xff1a;

最后我们就开始coding sparkstreaming的部分代码&#xff1a;&#xff08;主要要添加scala-sdk-2.10.6和spark-assembly-1.6.2-hadoop2.6.0等jar包&#xff09;
/**
* Created by mac on 16/8/12.
*/
import org.apache.spark.SparkConf
import org.apache.spark.streaming._;
object SparkStreaming
def main(args: Array[String])
//开本地线程两个处理&#xff0c;local[4]&#xff1a;意思本地起4个进程运行&#xff0c;setAppName("SparkStreaming")&#xff1a;设置运行处理类
val conf &#61; new SparkConf().setMaster("local[4]").setAppName("SparkStreaming")
//每隔5秒计算一批数据local[4]&#xff1a;意思本地起4个进程运行&#xff0c;setAppName("SparkStreaming")&#xff1a;设置运行处理类
val ssc &#61; new StreamingContext(conf, Seconds(5))
// 指定监控的目录
val lines &#61; ssc.textFileStream("/Users/mac/Documents/workspace/output")
//按\\t 切分输入数据
val words &#61; lines.flatMap(_.split("\\t"))
//计算wordcount
val pairs &#61; words.map(word &#61;> (word, 1))
//word &#43;&#43;
val wordCounts &#61; pairs.reduceByKey(_ &#43; _)
//排序结果集打印&#xff0c;先转成rdd&#xff0c;然后排序true升序&#xff0c;false降序&#xff0c;可以指定key和value排序_._1是key&#xff0c;_._2是value
val sortResult &#61; wordCounts.transform(rdd &#61;> rdd.sortBy(_._2, false))
sortResult.print()
ssc.start() // 开启计算
ssc.awaitTermination() // 阻塞等待计算
结果&#xff1a;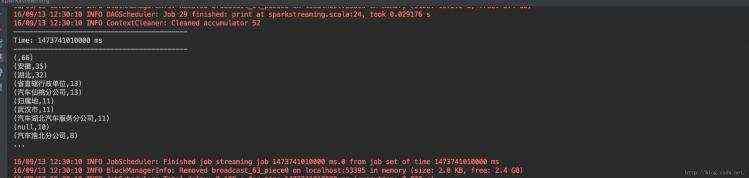
从结果可以看出&#xff0c;sparkstreaming每次会将设置的时间分片以内发生的增量日志进行一次批量处理&#xff0c;最终输出这个增量处理的结果。







 京公网安备 11010802041100号
京公网安备 11010802041100号